Innovative projects and the startup vibe – at 4soft, we know how to combine them!


Join us on a creative ride and learn how we reinvented Mueshi's fundraising platform.
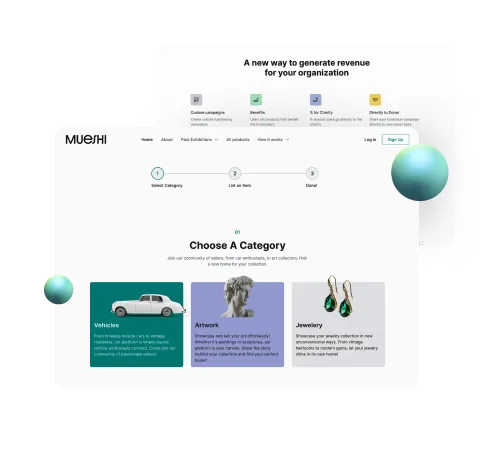

Imagine a world where investing in real estate is as easy as buying a cup of coffee. That's the future we're building together!
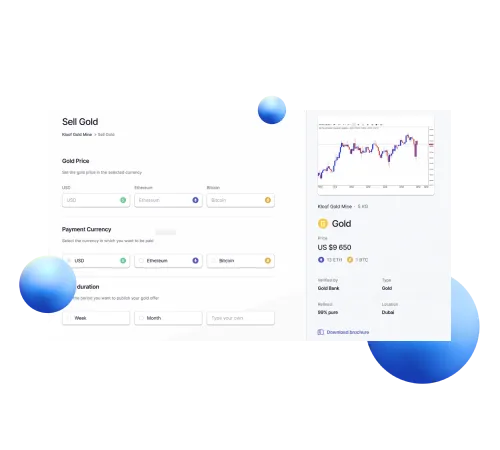

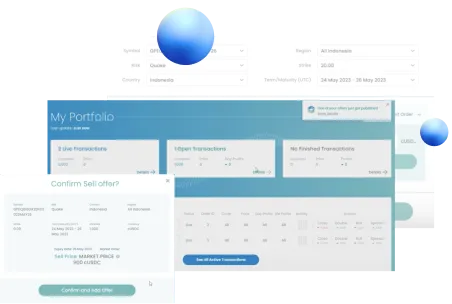
Charting New Frontiers in Insurance Technology through Advanced Blockchain Solutions.
Discover how our team of experts helped Artclear to launch its incredibly advanced and innovative product based on blockchain and IoT.


In-depth case study showcasing how a dedicated team revamped the frontend application for Profectus Group.


Discover how our team of experts helped URB-E launch its innovative mobile app for last-mile delivery.


Discover how our team of experts helped Tazz create captivating and usable UI designs for its DeFi applications.


Discover how our team of experts helped TerGo deliver a mobile application that tracks user activity and calculates their CO2 savings in real time.


Jsgenesis needed support in developing the frontend part of the project. Our experts stepped in and delivered fantastic work that received a lot of great feedback from the client and the Joystream community. Read this case study to learn more details about our wonderful collaboration with Jsgenesis.


4soft stepped in to help Artgeist keep up with the evolving business needs and develop a new internal system for managing all of the products, order fulfillment, and returns. Check out the case study to learn more about it.


Here’s another glimpse into an exciting project realizing for a broadcasting frequency rights authority in Asia.Read this case study to learn how we designed the system using blockchain technology.


How to automate a process and lift many tasks off a designer’s plate? Take a look at this case study to see how a well-designed application can become a game-changer for a glass manufacturing company.


Learn how the 4soft team helped this global leader in crypto risk management to build its state-of-the-art suite of compliance and investigative solutions explicitly built for cryptoassets.


Top-quality hardware has to go hand in hand with reliable software. Gigaset is currently building a new web application that allows users to manage their devices from one place. They reached out to 4soft during the project to ensure its timely delivery.


Our Machine Learning team had set out on a mission to contribute to this area of science. The goal was to create a machine learning-driven chatbot that could act as an online customer support service across different sectors, from eCommerce to legal and energy companies.


Imagine a concierge for travelers who books your plane and hotel, connects with other travelers, and ensures a perfect on-site experience through guide services and local activities. We locked all of these features in one app: Travel App.


Colony is a brand new community-driven ecosystem accelerator that aims to build a properly incentivized foundation for the next generation of Web3 applications built on Avalanche – an open, programmable smart contracts platform for decentralized applications.


Our team helped ZonGuru – the company behind the Amazon Seller Central – improve their platform by developing a plugin that optimizes a number of key sales processes and delivers a handy dashboard every seller wishes to have.


Development of a blockchain protocol for a Decentralized Finance application. The company’s mission is to remain chain agnostic and at the same time connect innumerable assets across multiple blockchains, allowing win-win transactions between borrowers and lenders.


When it comes to loyalty programs, customers value flexibility and solutions that are friendly and easy to use. This is a perfect opportunity to leverage Blockchain strengths.


License data are prone to fraud. An independent state telecommunication regulator asked us to create a platform to store help them store it in a safe and secure way.


The client came up with an innovative idea – a platform that utilizes double-intertwined blockchains to reduce money transfer costs. We built for him a safe and secure double blockchain platform.


The goal of the Torus Project was to create a cryptocurrency that will let people invest in renewable energy sources and benefit from their popularity. We created a perfect fundraising platform for them.

One of our US-based clients decided to create a new cryptocurrency and to conduct the Initial Coin Offering (ICO) process to facilitate business transactions.

Stability, predictability, security and transparency in operations
Customized solutions for increased efficiency and security
User-focused experience with intuitive design interfaces
Quality of work, reliability, and effective communication